Correcting Momentum in Temporal Difference Learning
In this paper we show that momentum becomes stale, especially in TD learning, and we propose a way to correct the staleness. This improves performance on policy evaluation.
See the full paper here.
We consider momentum SGD (Boris T Polyak
Some methods of speeding up the convergence of iteration methods, 1964Boris T Polyak, 1964): We can see momentum as a discounted sum of past gradients, I write here its simplest form for illustration:
What do we mean by ``past gradients''? Let's fold all data (input/target) in , and say gradients come from some differentiable function . Then:
More generally, consider that we may want to recompute the gradients for some data but for a different set of parameters , then we write:
This allows us to imagine some kind of ``ideal'' momentum, which is the discounted sum of the recomputed gradients for the most recent parameters, i.e. the sum of :
You can think of this as going back in time and recomputing, correcting past gradients:
Here the origin of the gradient arrows are perhaps decieving, since their new (corrected) source really is rather than . This makes the plot a bit more busy though, so I've exaggerated and lerped the gradients for dramatic effect:
The question now becomes, how do you do this without actually recomputing those gradients? If we did, that would cost a lot and in some sense just be equivalent to batch gradient methods.
We know that in DNNs, parameters don't change that quickly, and that, for well-conditioned parameters (which SGD may push DNNs to have, excluding RNNs) gradients don't change very quickly either. As such we should be fine with a local approximation. Taylor expansions are such approximations, and happen to kind of work ok for DNNs (David Balduzzi, Brian McWilliams, Tony Butler-Yeoman
Neural taylor approximations: Convergence and exploration in rectifier networks, 2017David Balduzzi et al., 2017).
So, instead of recomputing with our latest parameters , let's instead consider the Taylor expansion of around :
The derivative of turns out to be some kind of Hessian matrix (but not always exactly ``the Hessian'', as we'll see later with TD). We'll call this matrix .
When , then the above term essentially becomes an approximation of , which we'll call .
Now we can rewrite our ``ideal'' momentum, but using instead of the perfect , we'll write this as :
This still looks like we need to recompute the entire sum at each new , but in fact, since only needs to be computed once, this leads to a recursive algorithm.
You can think of as the correction term, the additive term coming from the Taylor expansion. This term is computed by keeping track of a ``momentum'' of the s, which we call .
Why is this important for Temporal Difference?
In TD, the objective is something like ( is optimization time, is the transition):
with meaning we consider it constant when computing gradients. This gives us the following gradient:
Recall that . roughly measures how changes as changes. One important thing to notice is that if we update , both and will change (unless we use frozen targets but we'll assume this is not the case).
This double change means that the gradients accumulated in momentum will be, in a way, doubly stale.
As such, when computing we need take take the derivative wrt both and (meaning ). This gives us the following for TD:
This allows us not only to correct for ``staleness'', but also corrects the bootstrapping process that would otherwise be biased by momentum. We refer to the latter correction of as the correction of value drift.
How well does this work in practice? For policy evaluation on small problems (Mountain Car, Cartpole, Acrobot) this works quite well. In our paper we find that the Taylor approximations are well aligned with the true gradients. We find that our method also corrects for value drift. This also seems to work on more complicated problems such as Atari, but the improvement is not as considerable.
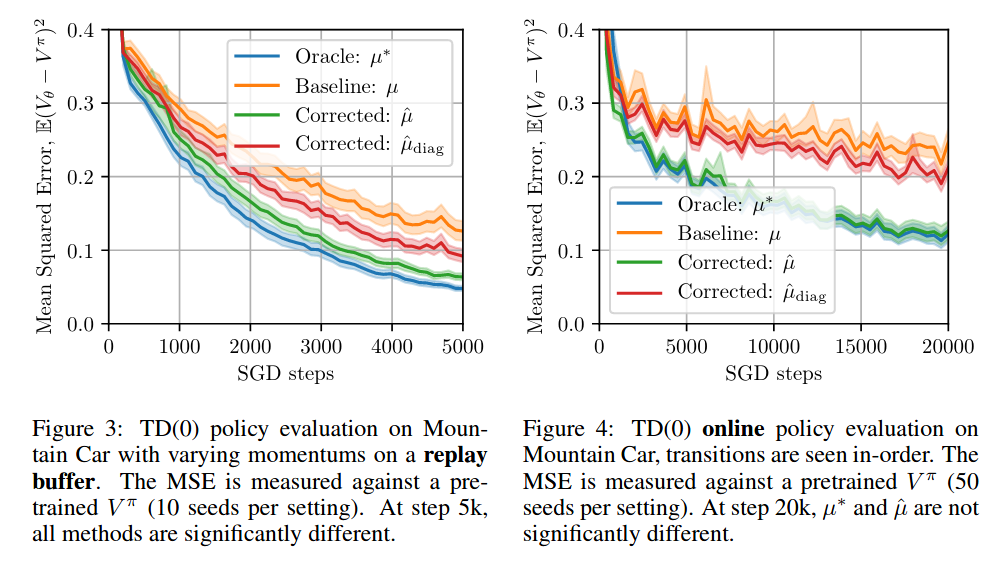
Find more details in our paper!